
One Gateway to Rule Them All
Last month I wrote about building an AI gateway in Rust. I described an OpenAI-compatible proxy with a two-tier cache, multi-tenant billing, and provider fallback. I called it a solid foundation and listed the things that weren’t done yet.
This is the sequel — what happened when the foundation started carrying weight.
Spoiler: it held. Less dramatically: it also broke in two places the first time a real project tried to use it. That’s how foundations work.
The “What’s Next” List, Revisited
The first post ended with a list of things the gateway needed. I had a budget enforcement layer that wasn’t enforcing budgets. AWS Bedrock was on the roadmap but not implemented. Adding Gemini was theoretically easy — one new struct implementing LlmProvider — but I hadn’t written it. Billing attribution required clients to manually call a separate /v1/track endpoint, which meant every integration had to remember an extra step.
That list is mostly done now.
Bedrock arrived first. The AWS SDK for Rust (aws-sdk-bedrockruntime) required more ceremony than the OpenAI or Anthropic adapters — AWS uses its own ConversationRole format, inference configuration maps differently from the OpenAI schema, and streaming comes through converse_stream() rather than an SSE endpoint. But the LlmProvider trait kept the blast radius contained. The rest of the gateway — cache, billing, fallback — didn’t notice a new provider existed.
Gemini came second. The prediction from the first post held up: implementing LlmProvider for Gemini took an afternoon. The abstraction earned its keep.
Automatic billing was the one that should have shipped on day one. The original design required downstream clients to POST to /v1/track after every LLM call — a second HTTP round-trip, an easy thing to forget, and a guaranteed source of billing gaps. The fix was straightforward: move cost recording into the response pipeline, fire it off in a background task, and stop making it the caller’s problem. Billing now happens on every request, invisibly, and clients don’t know it exists.
The most consequential change was making Bedrock the default provider. The gateway had been defaulting to OpenAI. Switching the DEFAULT_PROVIDER environment variable flipped the entire fleet in a single deploy.
The Architecture, Updated
The request flow from the original post still holds, but the provider layer looks different now:
POST /v1/chat/completions
│
├─ auth_middleware Bearer token + SHA-256 key lookup
│
├─ rate_limit_middleware Redis token bucket (60 rps / 10 burst)
│
├─ ModelCatalog "nova" → amazon.nova-lite-v1:0
│
├─ SemanticCache SHA-256 exact → cosine similarity @ 0.95
│
├─ Provider (ordered fallback chain)
│ 1. Bedrock AWS SDK, us-east-1 (default)
│ 2. OpenAI gpt-4o, gpt-4o-mini, o1
│ 3. Anthropic claude-opus-4-5, claude-haiku-4-5
│ 4. Gemini gemini-2.0-flash, gemini-1.5-pro
│
├─ Auto-billing fire-and-forget, never blocks response
│
└─ Return responseOne addition worth noting: ModelCatalog. The gateway now maintains an in-memory registry of model aliases. When a client requests "nova", the catalog resolves it to "amazon.nova-lite-v1:0" before the request leaves the machine. This turns model management into a gateway-side concern — downstream projects don’t embed provider-specific model IDs, and changing the default model is a one-line environment variable change, not a multi-repo find-and-replace.
There’s also a Redis-backed rate limiter now, where previously it was in-process only. This matters for horizontal scaling, but more immediately, it meant I could set per-key rate limits without worrying about process restarts resetting the bucket.
Security Hardening
The gateway handles API keys for multiple projects. Before migrating anyone onto it, it needed a more careful posture.
The changes were standard infrastructure hygiene, but worth enumerating: response headers (X-Frame-Options, CSP, HSTS), CORS policy locked to known origins, a 1 MB request size limit to stop accidental prompt injection at the HTTP layer, constant-time string comparison for token validation (not ==), and SHA-256 hashing of rate-limit keys so the Redis store never contains a raw API key.
None of this is exciting. All of it is necessary. A proxy that holds the API keys to four LLM providers and tracks spending across a multi-tenant system can’t afford to be careless about its own attack surface.
The First Migration
With the gateway hardened and Bedrock live, the migration campaign began.
The first project to route through the gateway was not the simplest one — it was the most actively developed. The reasoning was intentional: if anything was going to surface edge cases, a busy application with varied prompt patterns would find them faster than a quieter one.
The client-side change was three lines:
const client = new OpenAI({
apiKey: process.env.GATEWAY_API_KEY,
baseURL: process.env.AI_GATEWAY_BASE_URL + "/v1",
});That was it. No prompt changes, no schema changes, no logic changes. The OpenAI wire-format compatibility — the whole reason to build the gateway this way — paid its dividend on day one.
What wasn’t three lines was getting the gateway to behave identically to a direct provider call under production conditions.
Two bugs surfaced immediately.
The first was in streaming. The gateway was correctly forwarding SSE chunks from the upstream provider, but it wasn’t closing the stream with data: [DONE] in exactly the format the client’s parser expected. The chunk was there; the framing was slightly wrong. Nothing in unit tests had caught this because the tests compared payloads, not wire format precisely enough.
The second was subtler: the gateway was stripping a response header that one of the client libraries used to determine whether a response was cached. The downstream code was making decisions based on that header. Transparent proxies aren’t always transparent — there’s always something that wasn’t transparent enough.
Both bugs were small fixes. But they’re the kind of bugs you can only find by putting a real system behind the proxy and watching what actually happens.
The first migration is always the real integration test.
The Cascade
After the first migration, the rest moved quickly.
Project Migration Date Notes
────────────────────────────────────────────────────────────
product a week 1 first migration, found the streaming bugs
blog week 1 smoothest migration; exact same client config
mcp week 2 added ensemble routing through gateway
app week 2 replaced direct SDK calls to 3 providers
product b week 3 MCP server routes AI calls through gateway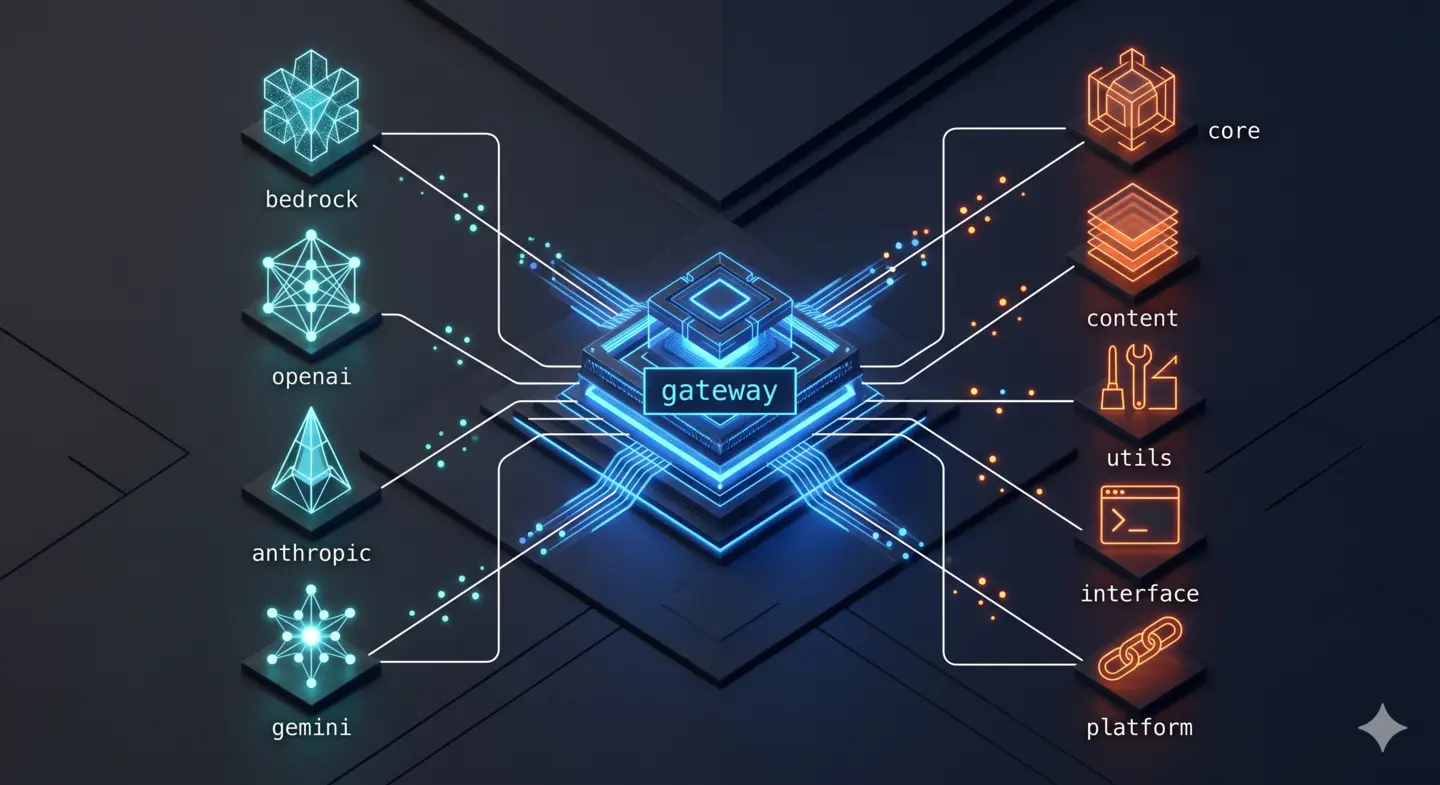
Five projects, all routing through the same gateway. The side effect I hadn’t anticipated: a unified cost dashboard appeared for free. Not because I built a new dashboard feature — because all the billing data was already flowing into the same tables. The usage_daily rollups that had been empty for a month suddenly had five organizations populating them in parallel.
Suddenly there was a single place to answer questions that previously required checking five different provider dashboards (or not answering them at all): which project is spending the most on LLM calls? Which model is being called most frequently? What does the cost trajectory look like week over week?
FinOps didn’t require new tooling. It emerged from centralizing the call site.
The FinOps Chapter: When 97% Isn’t an Exaggeration
The gateway was originally wired to use Claude Haiku 4.5 as its Bedrock default. Haiku is fast and capable — a reasonable choice for most of the workloads running through the system: summarization, tagging, classification, generating short metadata, answering bookmark-style questions.
Then I looked at the pricing for Amazon Nova Micro.
Model Input / 1M Output / 1M
──────────────────────────────────────────────────────
Claude Sonnet 4.6 $3.00 $15.00
Claude Haiku 4.5 $0.80 $ 4.00 ← was here
Amazon Nova Pro $0.80 $ 3.20
Amazon Nova Lite $0.06 $ 0.24
Amazon Nova Micro $0.035 $ 0.14 ← now here
The move from Haiku to Nova Micro cuts the per-token input cost by 97.5 percent. Output tokens go from $4.00 to $0.14 — a 97 percent reduction. For workloads where Nova Micro’s capability profile is sufficient, this isn’t a marginal improvement. It’s a different order of magnitude.
The decision was not “switch everything to the cheapest model.” It was more deliberate than that.
The gateway’s ModelCatalog means clients request a logical name — "nova", or "claude-haiku" if they specifically need it. The gateway resolves it to a concrete model at runtime. This separates the default from the maximum: the fleet runs on Nova Micro by default, but nothing prevents a specific workflow from requesting a more capable model by name when the task demands it.
The question worth asking honestly is: for the workloads actually running through this system, does Nova Micro produce results that are good enough? The answer, after a week of parallel testing, was yes — for the majority of them. Short-form generation, metadata extraction, classification, question answering over structured data: these don’t require the capability ceiling of Sonnet or GPT-4o. They require something fast, cheap, and reliably correct on well-defined tasks.
The cases where it fell short were also clarifying. There are a handful of prompts where the quality gap is visible enough to matter — longer synthesis tasks, nuanced editorial decisions, places where the instruction complexity exceeds what a micro model handles gracefully. These now explicitly request a higher-tier model. That’s the right design: reserve expensive capability for tasks that need it.
The Bedrock monthly budget went from $20 to $100 after this change — which might look like a contradiction. It isn’t. It’s the same logic as CPU preemption: when the marginal cost drops by an order of magnitude, you can afford more operations. The budget increase reflects confidence, not spend.
The pricing hot-reload mechanism — a five-minute background task that refreshes the PricingCache from the database — meant this change didn’t require a redeployment. Update the BEDROCK_MODEL_IDS environment variable, update the default in PricingCache, roll the ECS task definition. The old pricing entries were superseded by the new ones at the next cache refresh.
The Rest of the Month
The gateway was the through-line, but the rest of the portfolio didn’t stand still.
The dotfiles repository got a proper restructure — GNU Stow for symlink management, SOPS for encrypted secrets, a bootstrap script that works on both native Linux and WSL. The Zsh configuration grew up a bit: a proper plugin manager, Starship prompt, a few quality-of-life aliases that have already saved more keystrokes than they cost to write. Brazilian Portuguese cedilla support on a US keyboard, which turns out to require XCompose configuration and a GTK override and more yak-shaving than should be necessary.
The skills repository added twelve new engineering principles — DDD, Clean Architecture, Hexagonal Architecture, SOLID, Git best practices. Not as documentation, but as agent skills: structured prompts that give Claude Code (and other agents) grounding in specific design vocabularies before they start writing code. The CI pipeline for reviewing these skills uses an LLM-as-Judge pattern: five parallel agent reviews, each with a different evaluation lens, aggregated into a final score.
A separate service completed a framework migration that had been deferred for months — moving from an older MCP server protocol version to a newer one that uses Streamable HTTP instead of server-sent events. The previous implementation had a race condition in session state management that was acceptable at low traffic and intermittently reproducible under load. The new protocol version eliminated the problem at the architecture level rather than requiring a workaround.
An integrity domain launched: a query-driven API for federal sanctions lookups, pulling from public government data sources. Phase 1 is live. Phase 2 — scheduled ingestors that pre-load data rather than querying on demand — is the next thing on the list.

What a Month Actually Is
Thirty-one days, a little over five hundred commits across ten active projects. That sounds like a lot, and it is a lot. It also doesn’t mean five hundred things were completed — most commits are part of sequences, things that take three days to get right across a dozen attempts.
The real shape of this month was one central thing — the gateway reaching a state where it could actually carry the fleet — and four projects that got meaningfully further along because they weren’t blocked on infrastructure concerns.
There’s a kind of leverage in infrastructure work that’s easy to underestimate while you’re doing it and obvious in retrospect. Building the gateway took time and produced nothing user-visible. Migrating onto it took time and produced nothing user-visible. The FinOps work was a one-day effort. But together they mean every future LLM feature in every project starts from a fundamentally better position: cheaper, observed, resilient, and decoupled from any single provider’s decisions.
The Lifelong Learner’s Ledger
What did this month actually teach?
Rust’s async model in production — specifically the mental model shift required when fire-and-forget means spawning a task with tokio::spawn rather than “call this function and don’t await it.” The distinction matters when you’re reasoning about error handling and whether failures in billing should fail the request.
That “OpenAI-compatible” is a more specific claim than it sounds. Implementing the wire format is table stakes. The edge cases — stream framing, error response shapes, header conventions, how the client SDK interprets null versus absent fields — are where compatibility actually lives.
That a 97% cost reduction is only valuable if you know it’s happening. Before the gateway existed, I had no way to verify what the prior month’s model costs were across the portfolio. Now I do. FinOps requires observability first.
And maybe the thing that ties it together: there’s a difference between building for scale and building correctly. The gateway isn’t scaled for anything impressive. It runs on a t3.micro. It handles whatever traffic one person’s side projects generate. But the design — the trait abstraction, the graceful degradation, the pricing hot-reload, the ModelCatalog — is correct for the problem it solves. Correct systems are easier to scale than scaled systems are to correct.
The next thing on the list is more interesting than this one. That’s the only metric that really matters.
Related
- Building an AI Gateway from Scratch in Rust — the first post; architecture, caching, billing schema
- Why Executable Binaries Deserve More Attention — the companion piece on why shipping Rust binaries is sensible infrastructure thinking