
How magj.dev Grew Up
Three hundred commits is not a lot. It is also not a little. It is enough that, when I went back to read them in order, I could see the site changing its mind about what it wanted to be.
magj.dev started as a personal blog. The first commits are the boring kind: an Astro project, a Tailwind config, a Lighthouse audit that scored worse than I wanted. What it is now — a PWA with an SSR Lambda, a Content API behind CloudFront, an admin surface with MFA, and an LLM proxy hanging off a Function URL — was not on the roadmap. There was no roadmap.
This is the story of how the architecture got there one decision at a time.
1. Lighthouse as an SLA
The first real constraint I imposed on myself was that “best practices” in Lighthouse had to stay at 1.00. Not because anyone was watching, but because the moment you let one number slip, you stop watching the others.
That single rule shaped everything that came next. Astro was already the right tool — islands architecture, SSG by default, ship HTML and skip the framework runtime when you can. But the rule meant every interactive component had to justify its existence. The translate button, the summarize button, the language switcher, the install prompt — each one is a Svelte 5 island with client:load or client:visible, and each one had to prove it earned the bytes.
The CI pipeline runs Lighthouse with --disable-extensions because once a Chrome extension started polluting the console with its own warnings and dropping the best-practices score. That kind of fix is not glamorous. It is the kind of fix you make when you have decided the number matters.
2. The Day Markdown Wasn’t Enough
For a while, every post was a .md file in src/content/blog/. That is the purest form of an Astro site, and it works until it doesn’t.
What broke it was wanting to write notes — short, dated, frequent things that didn’t deserve a full blog post but deserved to exist somewhere. Treating each note as a markdown file plus a git commit plus a deploy felt absurd. So the architecture had to grow a backend.
The shape it took:
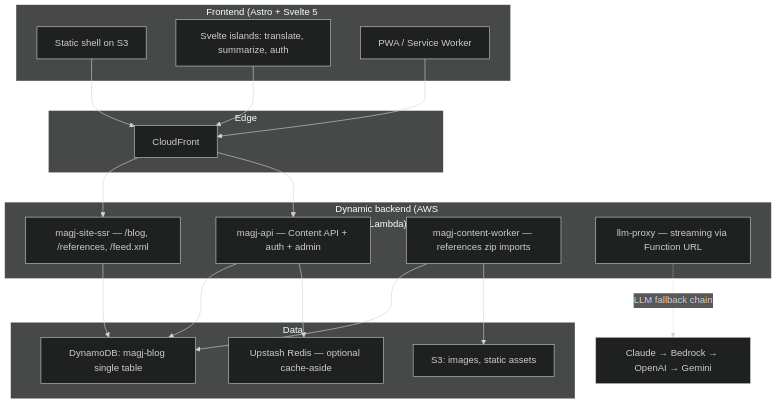
magj-api— a single AWS Lambda behind API Gateway. Auth and admin live here. The single-table DynamoDB design (magj-blog) holds usage, stats, the LLM cache, auth state, and — via a sparse GSI — the published blog and reference items themselves.magj-site-ssr— a separate Lambda behind a CloudFront-fronted Function URL. It serves the routes that need fresh content:/blog/*,/references*,/feed.xml. Everything else is still static HTML on S3.magj-content-worker— picks up reference imports as zip uploads.llm-proxy— a Function URL of its own, deliberately separate from API Gateway because streaming responses and long timeouts don’t get along with API Gateway’s defaults.
The site shell stays static. The dynamic parts load through the Content API with an optional Upstash Redis cache-aside in front of it. From a user’s point of view, nothing about the page tells them where the line is between “this came from S3” and “this came from a Lambda that hit a DynamoDB query.” That’s the point.
3. Streaming Stays Streaming
One thing I committed to early: any LLM-rendered content has to stream. If the cache has the answer, the cache streams it back as chunked output. It never gets served as a single blob just because it happens to be cached.
This sounds like a small detail. It isn’t. The moment you flip a streaming response into a buffered one, the experience changes — the page goes from “thinking out loud” to “blank for two seconds, then everything.” Caching is supposed to make things faster, not worse. So the cache layer in llm-proxy reads from DynamoDB and re-emits chunks at a rate that preserves the original cadence. Cached responses look identical to fresh ones. Users don’t get to tell which path served their request, and that is the entire goal.
The provider fallback chain — Claude → Bedrock → OpenAI → Gemini, via @wdotnet/ai-gateway — sits behind the same streaming contract. If Claude is slow, the proxy fails over without breaking the stream’s framing. The keys live in AWS Secrets Manager. Terraform creates placeholders; the real values are set by hand. There is exactly one operational reason for this: I don’t want secrets in Terraform state, and I am willing to accept the small amount of manual setup that buys.
4. The Admin Surface Earned Its Keep
The admin side of the site grew up later than the public side, but it grew up fast.
What started as a textarea is now a TipTap-based rich editor with sanitizers for notes, public note styles, and a publishing flow that writes through magj-api into the same DynamoDB table the public Content API reads from. Image generation is hooked up too — Dynamo prompt templates, a site policy layer, and either a direct Vertex AI call (NANO_BANANA_VERTEX_*) or a POST /generate against NANO_BANANA_API_URL, with an optional blocklist (IMAGE_GEN_BLOCKLIST) for prompts I don’t want to pay to find out about.
The interesting decision wasn’t the editor. It was the auth posture. A personal site doesn’t need MFA. I added it anyway: a full TOTP rollout with local QR generation. Not because the threat model demanded it, but because the cost of doing security badly later — once there’s actual data worth protecting — is much higher than the cost of doing it correctly now. Better to build the muscle on a low-stakes system than to discover you don’t have it on a high-stakes one.
5. Ephemeral Staging, Per PR
The deployment story is the one I’m most quietly proud of.
Every PR gets its own S3 bucket and CloudFront distribution. Open a PR, the staging environment spins up. Push a commit, it redeploys. Close the PR, it tears itself down. There is no shared “staging” environment that everyone has to coordinate around, because everyone is one person and one person doesn’t need a shared environment — they need one per branch.
The build itself is bun run build, which does a lot of things in sequence: regenerates images, pre-renders Mermaid diagrams to PNG (so the client never ships a Mermaid runtime), generates PWA screenshots, processes notes, runs astro build, packages the SSR Lambda zip via scripts/package-ssr-lambda.mjs, and writes a draft manifest. Build-time work over client-time work, every time. If a static asset can be generated at build, it is. The Mermaid PNGs in public/images/mermaid/ are checked into git for the same reason — deterministic, fast, and one fewer thing the browser has to load.
6. The Things I Reverted
A site like this has a graveyard, and the graveyard is part of the architecture.
I built site-wide internationalization, then reverted it. The implementation worked technically. It just didn’t work well — the experience of switching languages mid-article had rough edges I couldn’t smooth out without a serious rethink. So it came out. The decision rule I follow now: if a feature needs more research before it can ship cleanly, ship the absence of the feature instead of the unfinished version of it. Users don’t compare your site to its hypothetical better self; they compare it to whatever is in front of them. A small, polished site beats a big, rough one.
The same instinct applies to the smaller calls. Brazil as the default for country/language/phone format, because it’s where I am and where most of my readers are — and defaults that match the median user save more friction than any settings page can.
7. System Context, As of Today
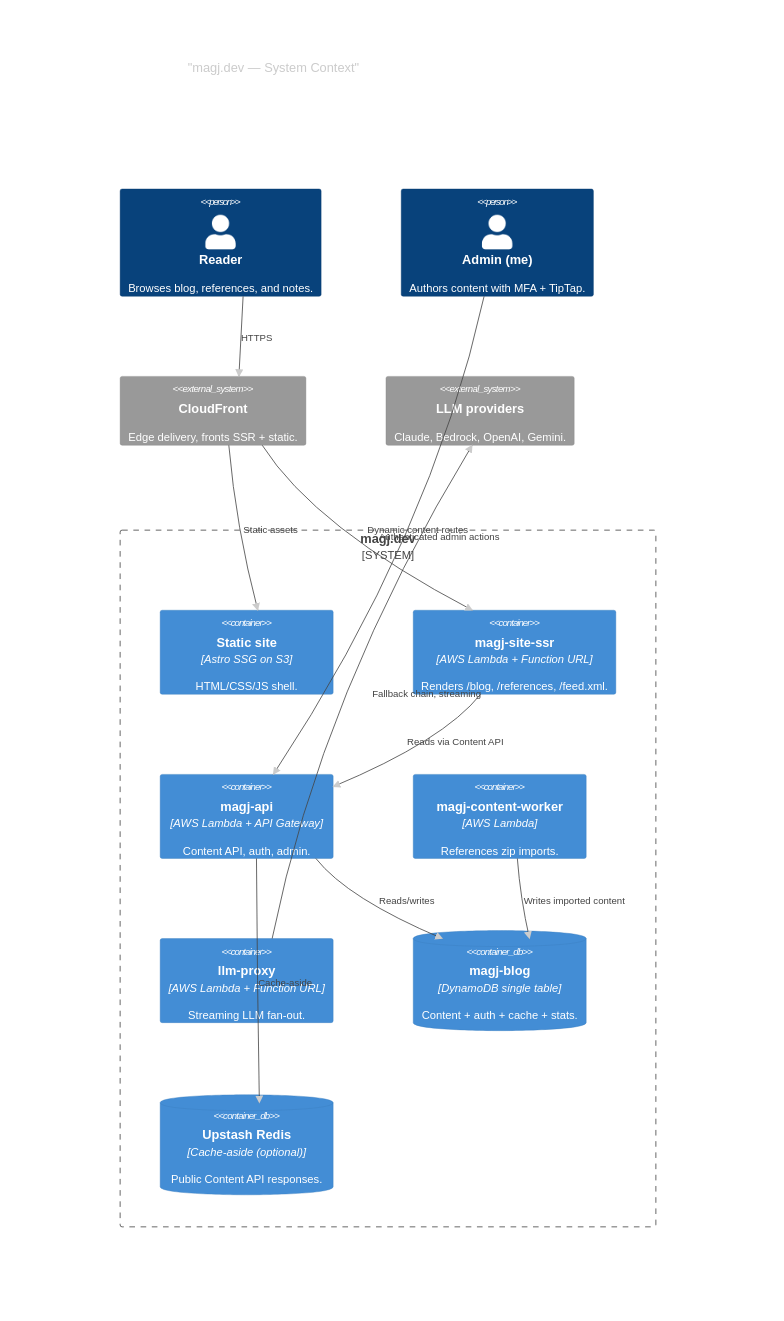
There is nothing in this diagram that I planned at the start. Every box appeared because some smaller version of itself stopped fitting.
8. What This Project Has Taught Me
A few things that didn’t make it into the commit messages:
Static is the default; dynamic is the exception you justify. Every dynamic surface in this site exists because there was no plausible static alternative. That ratio — most things static, a few things dynamic — keeps the operational cost near zero and the perceived performance near instantaneous. Inverting it would not have given me anything I needed.
Single-table DynamoDB punishes you up front and rewards you forever. Modeling everything (auth, usage, stats, the LLM cache, and the published content) on one table means thinking carefully about access patterns before you write the first query. It also means there’s exactly one piece of infrastructure to operate, monitor, and back up. The up-front cost is real. The ongoing simplicity is realer.
Streaming is a contract, not an implementation detail. The moment a cache decides to “just return the whole thing because we have it,” you’ve broken the contract the user implicitly relies on. Caches should be invisible. They should not change the shape of the response.
Reverting is a feature. The internationalization revert taught me more about how to evaluate a feature than any of the features that stayed in. There is a version of every project where someone keeps every half-finished idea, and it is always worse than the version where they don’t.
Per-PR staging is worth more than it looks like it should be. It’s the difference between “I’ll test this before merging” and “I already tested this; here’s the URL.” That gap is small in theory and enormous in practice.
The first commit set up an Astro project. The most recent one packaged an SSR Lambda. In between, the site quietly became infrastructure — small infrastructure, but infrastructure — and learned to behave like it.
The next commit will probably revert something.