
I Didn't Expect GPT-5.4 to Change My Coding Workflow. Then It Did.
I’m a real fan of Anthropic and their models for coding.
For a while, my default workflow was simple. I would use Opus for planning and for implementing the important parts of my applications. For lower-risk features, I would sometimes let Opus do the planning and Sonnet do the execution. I was genuinely happy with that setup. It was productive, predictable, and good enough that I was not actively looking for a replacement.
Then yesterday I started using OpenAI GPT‑5.4 with High and Extra High reasoning.
And I was astonished.
Not “this is good.” Not “this is competitive.” I mean that rare kind of astonishment you get when a tool quietly crosses a line and stops feeling like an assistant that is merely capable, and starts feeling like one that is thinking with real engineering pressure in mind.
That was the feeling.
This is not a takedown of Anthropic
Before going any further, let me make the most important point clear: this is not a post about Claude suddenly becoming bad. Quite the opposite. My starting point here matters precisely because I already had a strong opinion in Anthropic’s favor.
I already trusted Opus. I already liked the Opus-plus-Sonnet workflow. I already had a system that made sense to me in real projects.
So when I say GPT‑5.4 impressed me, I do not mean that it cleared a low bar.
I mean it beat an already high bar.
And honestly, that is what made the experience feel so strong.
What surprised me was not just the quality. It was the shape of the quality.
The first thing that stood out was planning.
Not longer planning. Better planning.
There is a difference.
A lot of strong models can produce a convincing plan. They can break the work into phases, mention the right abstractions, and sound like they know where they are going. GPT‑5.4 felt different to me because its planning was more likely to separate what was essential from what was merely nice to have. It was better at identifying the irreversible decisions early. It was better at noticing the hidden technical risks before implementation started. And it was better at sequencing the work in a way that reduced rework instead of just producing an elegant-looking outline.
That matters much more in practice than people sometimes admit.
The second thing was implementation quality.
Again, not in the shallow sense of “can it write code?” The frontier models can all write code. That is not the interesting threshold anymore. The interesting threshold now is whether the code feels like it expects to survive contact with a real codebase. Whether it has the right boundaries. Whether it makes good tradeoffs. Whether it handles the edge cases you would actually care about two weeks later when you are maintaining the feature instead of demoing it.
GPT‑5.4 gave me more of that feeling.
The third thing was the most impressive one: it spotted meaningful improvements over work that had already been produced by Opus.
That is where my reaction changed from “this is very good” to “okay, I need to pay attention.”
It is one thing for a model to generate something decent from scratch. It is another thing entirely for it to review already-strong work and still identify important improvements. At that point, you are not just looking at a model that can produce output. You are looking at a model that can raise the ceiling.
And for engineering work, that is the difference that matters.
My workflow, before and after
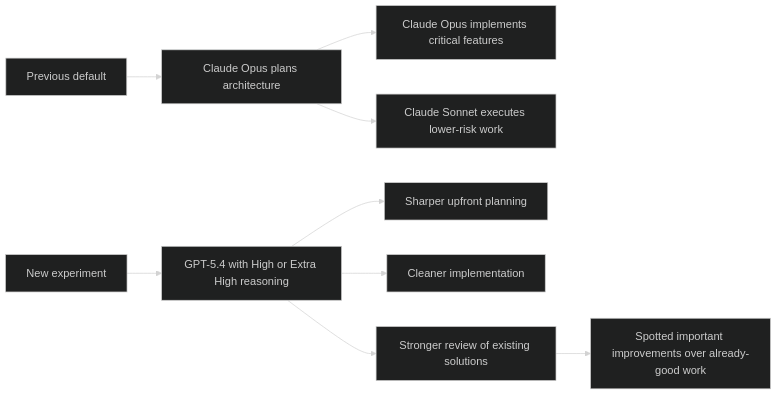
What changed for me is not that I suddenly want one model for everything.
What changed is that GPT‑5.4 earned the right to sit at the top of the stack for the work I care about most.
That is a different statement.
It means I am no longer thinking about it as “another strong option.” I am thinking about it as a serious default for planning, architecture, review, and implementation of the parts that actually matter.
The real benchmark was my own surprise
I know we all talk about benchmark charts, and they do matter. But if I am being honest, the benchmark that mattered most to me yesterday was internal.
I was already satisfied.
I was already biased in another direction.
I was not shopping for a new favorite.
And GPT‑5.4 still managed to make me stop and rethink my default workflow.
That is not a small thing.
When you already have a setup you trust, a new model does not win you over by being marginally better in some abstract sense. It wins by making you feel the difference in the work itself. In the plan. In the implementation. In the review pass. In the quality of the improvements it finds after the first draft already looks good.
That is exactly what happened to me.
Public benchmarks help explain the feeling, but they are not the feeling
If you look at the latest public disclosures from OpenAI and Anthropic, the broader picture makes this experience feel less mysterious. GPT‑5.4 shows very strong public results in coding, tool use, and computer-use evaluations. Anthropic’s latest Opus and Sonnet models remain extremely strong too. So this is not a story about one lab suddenly making the other irrelevant.
It is a story about the top end moving again.
And in my hands, for the kind of coding work I care about, GPT‑5.4 landed in a way that felt unusually complete.
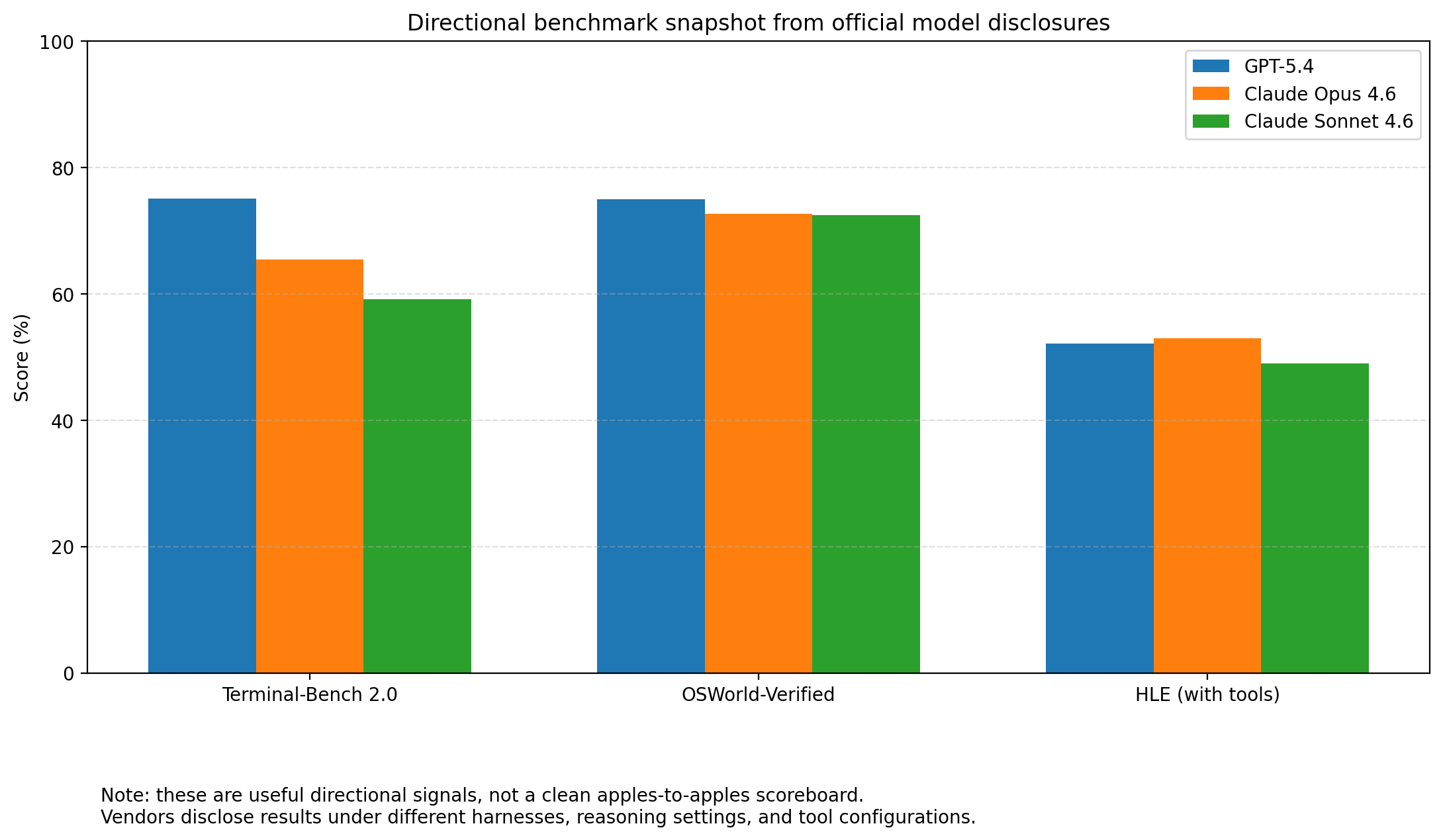
Here is a small directional snapshot from official public disclosures. I would treat it as signal, not gospel, because vendors do not always report under identical harnesses or settings:
| Evaluation | GPT‑5.4 | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|---|
| Terminal-Bench 2.0 | 75.1 | 65.4 | 59.1 |
| OSWorld-Verified | 75.0 | 72.7 | 72.5 |
| HLE (with tools) | 52.1 | 53.0 | 49.0 |
That table does not prove that one model is categorically superior in every environment. What it does show is that the current frontier is extremely close, extremely competitive, and no longer easy to summarize with old assumptions.
And that is exactly why hands-on experience matters so much.
Where I still give Anthropic a lot of credit
I do not want this post to read like a tribal victory lap, because that would miss the point entirely.
Anthropic earned my trust for a reason. Opus has been excellent. Sonnet has been a very smart way to balance quality, speed, and cost on a lot of practical work. Nothing about yesterday erased that.
If anything, the strength of my reaction says more about how good Anthropic already was than it does about anything else. For GPT‑5.4 to stand out this clearly, it had to outperform something I already respected a lot.
That is the highest compliment I can give it.
My current takeaway
Right now, my takeaway is simple.
If you care about serious coding work, serious planning, and serious review quality, you should not rely on old loyalties or old impressions. Test again. Put the models in front of work that matters. Give them ambiguous architecture problems. Give them code that is already decent and ask them to improve it. Give them the tasks where taste, prioritization, and technical judgment matter more than raw syntax generation.
That is where I felt the difference.
And at least today, GPT‑5.4 feels like the strongest model I have personally used for that class of work.
That sentence surprises me a little bit.
Which is exactly why I am writing this post.
Final thought
The best compliment I can pay GPT‑5.4 is this:
It impressed me when I did not particularly want to be impressed.
I came in as someone who already had a working preference, already had a trusted workflow, and already had genuine respect for Anthropic’s models.
I left thinking: I need to rethink my default.
That is a big deal.
And if you are doing real software engineering work with these models every day, I suspect you know exactly why.